Chat mit Dokumenten
Der nächste Schritt in der Informationsverarbeitung
Anstatt sich auf öffentliche Datensätze und allgemeines Wissen zu verlassen, generiert "Chat mit Dokumenten" kontextspezifische Antworten und Analysen auf Basis deiner vertrauenswürdigen internen Quellen. Lade deine Dokumente hoch und nutze diese als Grundlage zum Beantworten von Fragen im Chat!
Lösung von Datenbeschränkungen
Wenn du Fragen an ein Sprachmodell stellst, bist du von dem Datensatz abhängig, mit dem das Modell trainiert wurde. Dies ist in der Regel Informationen, die aus dem Internet stammen. Nicht-öffentliche Quellen sind wahrscheinlich nicht in diesem Datensatz enthalten. Indem du deine Dokumente als Quelle für den Chat verwendest, stellst du sicher, dass das Modell über die Informationen verfügt, die du zur Beantwortung deiner Fragen benötigst.
Möglichkeiten mit deinen Dokumenten
Du kannst Fragen zu deinen Dokumenten stellen, wie z.B. die Hauptpunkte eines Dokuments aufzulisten oder das Dokument zusammenzufassen. Auch kannst du spezifische Analysen vom Sprachmodell mit Hilfe deines eigenen Datensatzes durchführen lassen.
Nachteile des dokumentbasierten Chats
Das Hochladen und Verarbeiten von Dokumenten sind zusätzliche Schritte, die du nicht durchführen musst, wenn du auch ohne den Kontext spezifischer Informationen problemlos Antworten erhalten kannst. Außerdem dauert es länger, eine Antwort zu generieren, da zunächst die erforderlichen Informationen aus dem Dokument abgerufen werden müssen, bevor die Anfrage an das Sprachmodell gesendet werden kann.
Hinter den Kulissen des Chats mit Dokumenten
Der Text aus den Dokumenten, die du hochlädst, wird aus dem Dokument extrahiert und in Stücke aufgeteilt. Diese Stücke haben eine feste Anzahl von Zeichen (1024 Zeichen), und wir haben auch eine Überlappung (128 Zeichen) zwischen den Stücken festgelegt. Jedes Textstück wird als Vektor in einer Vektordatenbank gespeichert. Bei jeder Frage wird aus diesen Daten eine Auswahl basierend auf der Ähnlichkeit mit der gestellten Frage getroffen.
Auswahlprozess von Dokumentfragmenten
Die Textstücke wurden bereits in Vektoren umgewandelt. Vektoren haben mehrere Dimensionen, die angeben, wie "gleich" dieser Text zu anderen Texten ist. Denk an das RGB-Farbsystem. Eine Farbe mit ähnlichem RGB-Wert ist auch eine ähnliche Farbe, aber leicht anders. Die Vektordatenbank ermöglicht es uns, die Textstücke basierend auf der gestellten Frage sortiert und gefiltert abzurufen. Wir wählen maximal 100 Textstücke von 1024 Zeichen aus, um sie mit der Frage zu senden.
Geeignete Modelle für dokumentbasierten Chat
Wir haben Modelle mit großem Kontextfenster ausgewählt, um das Chatten mit Dokumenten zu ermöglichen. Verwenden Sie dafür vorzugsweise ein hochwertiges Sprachmodell aus dem zentralen Modellkatalog.
Geeignete Modelle haben ausreichend Kontextkapazität und gute Dokumentanalyse, zum Beispiel die hochwertigen Modelle von OpenAI, Claude, Google oder Europäischer KI.
Wähle ein oder mehrere Dokumente
Du kannst den Dateimodus aktivieren, indem du auf die Büroklammer rechts neben der Fragenleiste klickst. Du kannst bis zu 10 Dateien zum Chatten auswählen.
Wenn das gewählte Modell nicht geeignet ist, wird automatisch ein geeignetes Modell aus dem aktuellen Katalog ausgewählt.
Du chattest mit diesen Dokumenten, solange der Dateimodus aktiviert ist.
Pro Datei verarbeiten
Neben dem Chatten mit Dokumenten bietet AI-School auch die Möglichkeit, einen Prompt separat auf jedes Dokument anzuwenden und individuelle Antworten zu erhalten. Diese Funktion heißt Pro Datei verarbeiten.
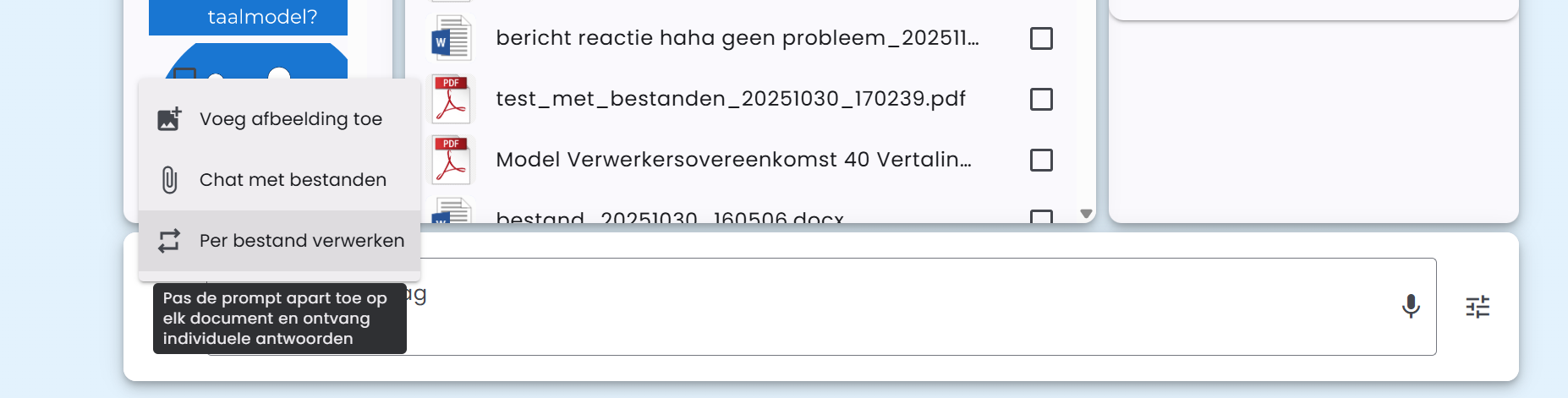
Diese Funktion kann in Kombination mit "Chat mit Dateien" verwendet werden.
Mögliches Szenario
Ein praktisches Beispiel für die Verwendung von "Pro Datei verarbeiten":
- Du lädst den Test und das Antwortmodell hoch und aktivierst sie bei Chat mit Dateien
- Du lädst mehrere eingereichte Tests hoch und aktivierst sie bei Pro Datei verarbeiten
- Du formulierst einen Prompt, der auf alle Dateien einzeln angewendet wird
Auf diese Weise kannst du beispielsweise alle eingereichten Tests automatisch auf Basis des Antwortmodells bewerten lassen.
Es gilt ein Maximum von 30 Dateien für die Funktion "Pro Datei verarbeiten".
Unterstützte Dateitypen
AI-School unterstützt verschiedene Dateitypen für den Dokumentenchat:
- PDF-Dateien mit der Endung .pdf
- Word-Dateien mit der Endung .docx
- CSV-Dateien mit der Endung .csv
- JSON-Dateien mit der Endung .json
- Textdateien mit der Endung .txt
- Audio- und Videodateien mit den Erweiterungen 'mp3', 'mp4', 'mpeg', 'mpga', 'm4a', 'wav' oder 'webm'
Mit Audio- oder Videodateien chatten
Bei Audio- oder Videodateien transkribiert AI-School die Datei zuerst über den konfigurierten Transkriptionsanbieter, zum Beispiel OpenAI oder Europäische KI. Die konkreten Modelle stammen aus dem zentralen Modellkatalog.
Bei Gesprächen kann die Transkription Zeitblöcke und Sprecherlabels enthalten, wenn das gewählte Modell dies unterstützt. Danach kann ein geeignetes Textmodell Zeichensetzung, Rechtschreibung, Sprecherlabels und Fachbegriffe korrigieren.
Nach der Transkription gilt derselbe Ablauf wie bei PDF- oder Word-Dokumenten.
Audio- und Videomodelle haben je nach Anbieter und Modell unterschiedliche Grenzen für Dateigröße und Dauer. Lange Dateien können daher anders verarbeitet werden als kurze Dateien. Wenn die Verarbeitung fehlschlägt, prüfe den Dateistatus und versuche es erneut oder liefere die Datei in kleineren Teilen.
Dateien, die du als Beispiel herunterladen kannst
Dateiverarbeitung und Wiederverwendung
Hochgeladene Dateien werden zuerst verarbeitet, bevor AI-School ihre Inhalte in Chats, Assistenten und Workflows verwenden kann. Wenn die Verarbeitung fehlschl?gt, erh?lt die Datei einen Fehlerstatus und kann erneut hochgeladen oder in der Dateiverwaltung erneut verarbeitet werden.
Bei PDFs kann AI-School die normale Textebene verwenden und bei Bedarf eine umfassendere PDF-Analyse durchf?hren. Das ist hilfreich bei gescannten Dokumenten, ausgef?llten Formularen, handschriftlichen Notizen, eingekreisten oder unterstrichenen Antworten, Tabellen und visuellen Informationen. Gro?e PDFs k?nnen w?hrend der Verarbeitung in kleinere Teile aufgeteilt werden.
Wenn ein Formular oder Workflow eine Datei ben?tigt, k?nnen Sie eine neue Datei hochladen oder eine vorhandene Datei aus dem Medienmanager ausw?hlen. Dateien, die ?ber ein solches Formular hinzugef?gt werden, stehen dem Assistenten f?r diesen Chat zur Verf?gung, werden aber nicht automatisch f?r normale Chatfragen ausgew?hlt.
Markdown-Dateien mit der Erweiterung .md werden ebenfalls unterst?tzt.