Chatta med dokument
Nästa steg i informationsbehandling
I stället för att förlita sig på offentliga dataset och allmän kunskap genererar "Chatta med Dokument" kontextspecifika svar och analyser baserade på dina betrodda interna källor. Ladda upp dina dokument och använd dessa som grund för att besvara frågor i chatten!
Lösningar av datarestriktioner
Om du ställer frågor till en språkmodell är du beroende av datasetet som modellen tränats på. Det är i allmänhet information hämtad från internet. Icke-offentliga källor finns troligen inte i detta dataset. Genom att använda dina dokument som källa för chatten kan du vara säker på att modellen har den information du behöver för att besvara dina frågor.
Möjligheter med dina dokument
Du kan ställa frågor om dina dokument, som att nämna huvudpunkterna i ett dokument eller sammanfatta dokumentet. Du kan också låta språkmodellen utföra specifika analyser med hjälp av din egen dataset.
Nackdelar med dokumentbaserad chat
Att ladda upp dokument och behandla dem är extra steg som du slipper om du klarar dig utan sammanhanget av specifisk information. Det tar också längre tid att generera ett svar eftersom nödvändig information ur dokumentet först måste hämtas innan förfrågan skickas till språkmodellen.
Bakom kulisserna av chatta med dokument
Texten från de dokument du laddar upp hämtas ur dokumentet och delas upp i bitar. Dessa bitar har ett fast antal tecken (1024 tecken) och vi har även en overlap inställd (128 tecken) mellan bitarna. Varje textstycke lagras som en vektor i en vektor-databas. Vid varje fråga görs ett urval ur dessa data baserat på likhet med frågan som ställs.
Urvalsprocess för dokumentfragment
Textbitarna har redan omvandlats till vektorer. Vektorer har flera dimensioner som anger hur "lika" denna text är med annan text. Tänk på RGB-färgnyanssystemet. En färg med liknande RGB-värde är också en lik färg men lite annorlunda. Vektor-databasen gör det möjligt för oss att hämta textbitar ordnade och filtrerade baserat på frågan som ställs. Vi väljer upp till 100 textbitar à 1024 tecken att skicka med frågan.
Passande modeller för dokumentbaserad chat
Vi har valt modeller med stort kontextfönster för att möjliggöra chat med dokument. Vi vill kunna skicka upp till 100 bitar på 1024 tecken. Det är mer än 100 000 tecken. Använd helst en högkvalitativ språkmodell från central modellkatalog.
Passande modeller är modeller med tillräckligt kontextutrymme och bra dokumentanalys, som högkvalitetsmodeller från OpenAI, Claude, Google eller Europeisk AI.
Välj ett eller flera dokument
Du kan slå på filläge genom att klicka på gem-ikonen till höger om frågefältet. Du kan välja upp till 10 filer att chatta med.
Filer som du laddar upp behandlas först. När behandlingen är klar kan AI-School använda innehållet i chatten, i assistenter och i arbetsflöden. Om behandlingen misslyckas får filen ett felstatus och du måste ladda upp igen eller behandla igen.
När du börjar chatta med dokument kontrolleras om språkmodellen är lämplig för chat med dokument. Om den inte är det väljs automatiskt en passande modell från den aktuella katalogen.
Du chattar med dessa dokument så länge fil-läget är påslaget.
Filhantering och ny behandling
I Filhantering ser du filerna du har laddat upp eller som AI-School har skapat. För PDF-filer kan du via åtgärdsmenyn behandla en fil på nytt. Detta ersätter den befintliga textutvinningen med en ny behandling.
För PDF:er kan AI-School använda den vanliga textlagret och när så behövs genomföra en mer omfattande PDF-analys. Denna analys är särskilt användbar vid:
- skannade PDF-filer
- ifyllda formulär
- handskrivna svar
- ringade eller understrukna alternativ
- tabeller, figurer och annan visuell information
Vid stora PDF-filer kan bearbetningen ta längre tid. AI-School delar upp stora dokument vid behov så att även längre PDF:er kan bearbetas.
Välj befintliga filer
När ett formulär eller arbetsflöde begär en fil kan du inte bara ladda upp nya filer utan även välja befintliga filer via mediabryggan. Så behöver du inte ladda upp ett prov, bedömningsmodell eller annat brondokument varje gång.
Filer som tillförs via ett sådant formulär visas bland assistentfilerna i chatten. De väljs inte automatiskt för vanliga chatfrågor förrän du aktiverar dem där själv.
Bearbeta per fil
Förutom chatten med dokument erbjuder AI-School även möjlighet att tillämpa en prompt separat på varje dokument och få individuella svar. Denna funktion kallas Bearbeta per fil.
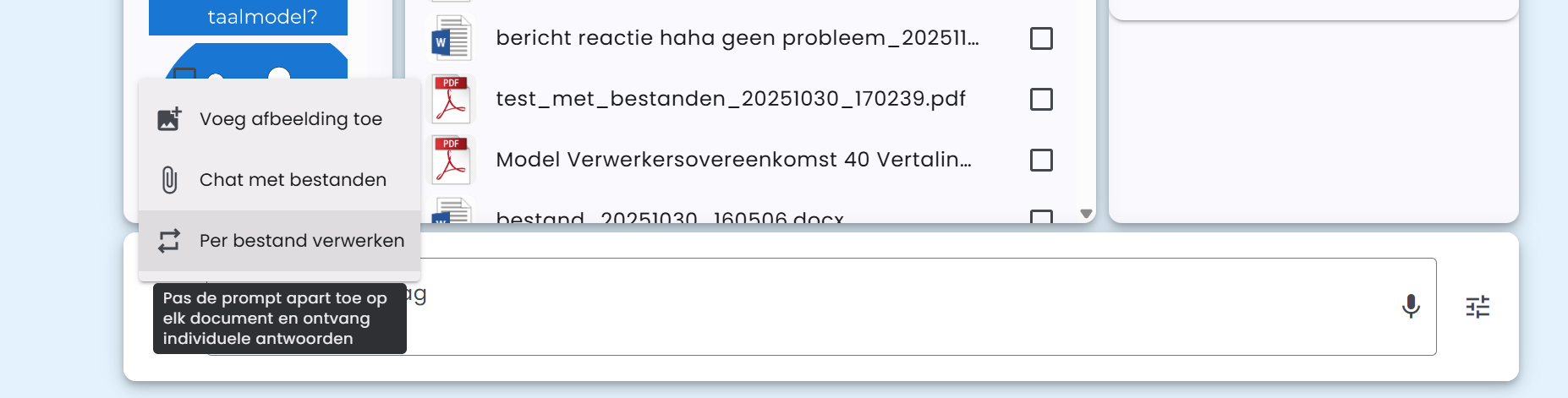
Denna funktion kan användas i kombination med "Chatta med filer".
Möjligt scenario
Ett praktiskt exempel på användning av "Bearbeta per fil":
- Du laddar upp provet och svarsmall och aktiverar detta vid Chatta med filer
- Du laddar upp flera inlämnade prov och aktiverar detta vid Bearbeta per fil
- Du formulerar en prompt som tillämpas på varje fil individuellt
På så vis kan du till exempel låta alla inlämnade prov automatiskt bedömas utifrån svarsmallen.
Det finns en gräns på 30 filer för funktionen "Bearbeta per fil".
Stödja filtyper
AI-School stöder olika filtyper för chatten med dokument:
- PDF-filer som slutar på .pdf
- Word-filer som slutar på .docx
- CSV-filer som slutar på .csv
- JSON-filer som slutar på .json
- Textfiler som slutar på .txt
- Markdown-filer som slutar på .md
- Ljud- och videofiler med extensionerna 'mp3', 'mp4', 'mpeg', 'mpga', 'm4a', 'wav' eller 'webm'
Chatta med ljud- eller videofiler
För ljud- eller videofiler transkriberar AI-School först filen via den konfigurerade transkriptionsleverantören, till exempel OpenAI eller Europeisk AI. De konkreta modellerna kommer från den centrala modellkatalogen.
Vid samtal kan transkriptionen innehålla tidsblock och talaretiketter när den valda modellen stöder det. Därefter kan en lämplig textmodell korrigera interpunktion, stavning, talaretiketter och facktermer.
Efter transkriptionen används samma process som för PDF- eller Word-dokument.
Ljud- och videomodeller har leverantörs- och modellspecifika gränser för filstorlek och längd. Långa filer kan därför bearbetas annorlunda än korta. Om bearbetningen misslyckas, kontrollera filstatus och försök igen eller lämna filen i mindre delar.